一般来说一次IO操作包含两个步骤
- 内核准备数据
- 数据从内核拷贝到用户进程
常见的IO模型主要有以下几种
- 阻塞IO
- 非阻塞IO
- 多路复用IO
- 信号驱动IO
- 异步IO
阻塞IO
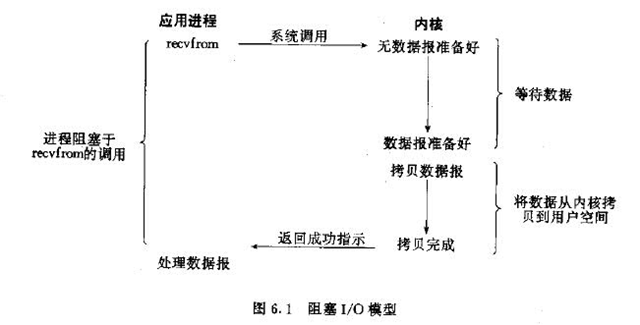
在读写过程中发生阻塞。用户线程发生IO请求之后,内核就会去进行处理,在处理完成之前,就会一直阻塞着用户的线程,只有当数据准备完成之后,内核才会将数据拷贝到用户线程中,然后用户线程才会结束阻塞状态。
非阻塞IO
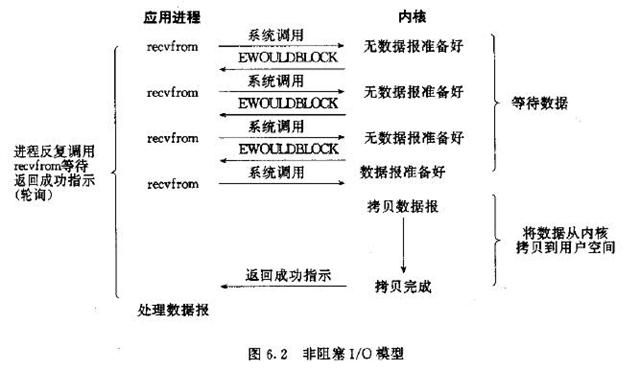
用户进程发起IO请求之后,如果数据还没有准备好,内核会回复还未就绪,然后进程不停的去轮询,直到数据准备就绪。当数据准备好之后,就会执行数据的拷贝,将数据从内核拷贝到用户空间,完成之后就会结束该次IO请求。
类似于下面代码
1 | while(true){ |
非阻塞IO虽然不会阻塞线程,但是因为有轮询,所以会不停的消耗CPU,倒是资源的浪费。
多路复用IO
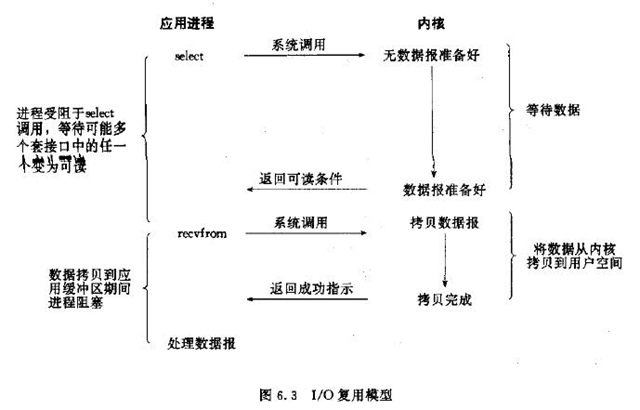
多路复用,是通过使用一个线程来监听所有的socket,一旦有一个socket的数据就绪了,就会通知对应的socket去进行数据的拷贝。使用多路复用会阻塞进程,跟阻塞IO有点类似。多路复用一般搭配非阻塞IO,因为多路复用里面会有很多个socket连接,可能有些有返回,有些没有返回,在处理当前的socket的时候,也不知道下一个是否会是就绪,如果使用阻塞io,就会阻塞住整个线程
在发生实际的IO拷贝之前,多路复用模型并不会占用IO资源。
异步IO
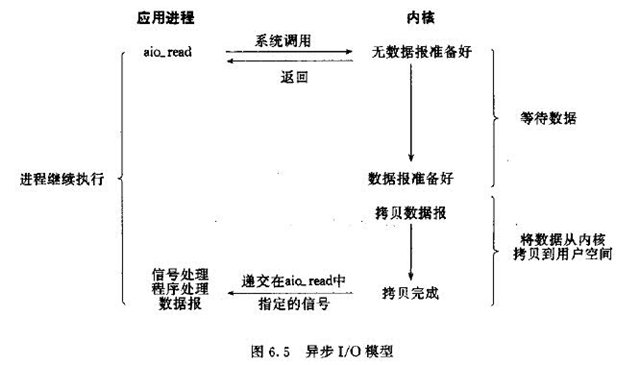
异步IO是一种异步的返回方式,用户发起IO请求之后,就会立即返回,然后去处理其他事情。对内核而言,接收到用户的IO的请求之后,会立马返回,不会阻塞。当数据准备好之后,会将数据从内核拷贝到用户空间去,完成之后会向用户进程发送一个信号,通知操作完成。对于用户而言,只需要发起请求即可,然后等待信号,就可以直接去使用数据了,不用关心具体的IO操作
信号驱动IO

用户进程发起IO请求之后,会为socket注册一个信号函数,然后用户进程继续执行,内核开始准备数据。在内核数据准备完成之后,会调用信号函数通知用户,然后有用户开始请求数据的拷贝,只到拷贝完成。该IO主要用于UDP中。
多路复用IO中的selector
在说到IO的内容时,必不可少的一个知识点就是文件描述符fd。在linux中,万物都可看做一个文件,而linux是通过文件描述符来表示一个文件的,之后的操作都会基于fd来进行操作。其中有三个标识符,0,1,2是linux系统共专用的,分别用来表示标准输入,标准输出以及标准错误。一个socket请求,对linux而言也是一个fd。
IO复用,指的是多个请求复用一个进程来进行io操作,虽然同一时间可能会有很多个请求执行IO操作,但是大部分的数据可能还没有准备好,因此并不会实际执行IO操作,一旦有数据可以就绪了,就会执行IO服务。
IO复用中有三种方式来监听数据的状态
- select
- poll
- epoll
select()
在调用select之后,就会对当前进程阻塞,直到有fd就绪,或者等待超时,然后函数才会进行返回。在单个进程上面,select监听的文件描述符的最大数量为32位系统是1024,64位系统是2048。
在调用开始的时候,会把所有的fd拷贝到内核中,然后在内核中对所有的fd进行遍历,在fd很大的时候,select方式的效率会很低。
在有数据就绪的时候,select并不知道是哪个就绪了,因此只能通过轮询所有的fd来找到就绪的fd,来执行操作
#####poll()
本质上跟select差不多,只是poll是使用链表来存储fd,因此没有最大连接数的限制
epoll()
epoll有两种触发方式,ET和LT。ET方式,是在内核通知fd就绪之后,用户可以去执行操作,如果不执行的话,之后内核还是会继续通知。LT方式是就绪之后只会 通知一次,即使没有处理也不会再次通知,直到下一次有新的请求就绪之后才会进行下一次通知。
epoll中有三个函数
- int epoll_create(int size); 建立一個 epoll 对象,并传回它的id
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 事件注册函数,将需要监听的事件和需要监听的fd交给epoll对象
- int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); 等待注册的事件被触发或者timeout发生
在数据准备就绪的时候,就会被就绪的fd加入到一个就绪队列,然后epoll_wait会查看是否有就绪的fd,如果有的话,就唤醒就绪队列上面的等待者,然后调用回调函数.
在有大量的空连接的情况下,epoll的方式会比poll和select更加高效,因为它并不需要轮询所有的fd。
在连接数不多的情况下,poll和select会更加高效,因为epoll的通知需要很多的函数回调。
epoll 和select poll的区别
- epoll没有文件数量的限制,epoll的最大文件数量跟linux系统支持打开的文件数量有关,而select在32上只支持1024,64位支持2048。poll因为使用链表,也没有限制
- 通知方式不同,select和poll是通过轮询,找到就绪的fd,而epoll是在fd就绪之后,会加入到就绪队列,然后只需要操作就绪队列中的fd即可,避免了无效的遍历。一个是主动轮询,一个是被动触发
- epoll和poll因为需要遍历,所以需要把fd集合从进程中移动到内核中,该操作需要对资源进行小号。